
部署hadoop分布式文件系统一、首先介绍安装环境: Hadoop是Apache开源组织的一个分布式计算开源框架,在很多大型网站上都已经得到了应用,如亚马逊、Facebook和Yahoo等等。对于我来说,最近的一个使用点就是服务集成平台的日志分析。服务集成平台的日志量将会很大,而这也正好符合了分布式计算的适用场景(日志分析和索引建立就是两大应用场景)。 Hadoop框架中最核心的设计就是:MapReduce和HDFS。MapReduce的思想是由Google的一篇论文所提及而被广为流传的,简单的一句话解释MapReduce就是“任务的分解与结果的汇总”。HDFS是Hadoop分布式文件系统(Hadoop Distributed File System)的缩写,为分布式计算存储提供了底层支持。 MapReduce从它名字上来看就大致可以看出个缘由,两个动词Map和Reduce,“Map(展开)”就是将一个任务分解成为多个任务,“Reduce”就是将分解后多任务处理的结果汇总起来,得出最后的分析结果。这不是什么新思想,其实在前面提到的多线程,多任务的设计就可以找到这种思想的影子。不论是现实社会,还是在程序设计中,一项工作往往可以被拆分成为多个任务,任务之间的关系可以分为两种:一种是不相关的任务,可以并行执行;另一种是任务之间有相互的依赖,先后顺序不能够颠倒,这类任务是无法并行处理的。回到大学时期,教授上课时让大家去分析关键路径,无非就是找最省时的任务分解执行方式。在分布式系统中,机器集群就可以看作硬件资源池,将并行的任务拆分,然后交由每一个空闲机器资源去处理,能够极大地提高计算效率,同时这种资源无关性,对于计算集群的扩展无疑提供了最好的设计保证。(其实我一直认为Hadoop的卡通图标不应该是一个小象,应该是蚂蚁,分布式计算就好比蚂蚁吃大象,廉价的机器群可以匹敌任何高性能的计算机,纵向扩展的曲线始终敌不过横向扩展的斜线)。任务分解处理以后,那就需要将处理以后的结果再汇总起来,这就是Reduce要做的工作。 adidas zx 750 damskie  上图就是MapReduce大致的结构图,在Map前还可能会对输入的数据有Split(分割)的过程,保证任务并行效率,在Map之后还会有Shuffle(混合)的过程,对于提高Reduce的效率以及减小数据传输的压力有很大的帮助。 South Carolina Gamecocks Jerseys 后面会具体提及这些部分的细节。 HDFS是分布式计算的存储基石,Hadoop的分布式文件系统和其他分布式文件系统有很多类似的特质。分布式文件系统基本的几个特点: 1. 对于整个集群有单一的命名空间。 new balance 1600 daytona ronnie fieg 2. 数据一致性。 Jake Arrieta Authentic Jersey 适合一次写入多次读取的模型,客户端在文件没有被成功创建之前无法看到文件存在。
上图就是MapReduce大致的结构图,在Map前还可能会对输入的数据有Split(分割)的过程,保证任务并行效率,在Map之后还会有Shuffle(混合)的过程,对于提高Reduce的效率以及减小数据传输的压力有很大的帮助。 South Carolina Gamecocks Jerseys 后面会具体提及这些部分的细节。 HDFS是分布式计算的存储基石,Hadoop的分布式文件系统和其他分布式文件系统有很多类似的特质。分布式文件系统基本的几个特点: 1. 对于整个集群有单一的命名空间。 new balance 1600 daytona ronnie fieg 2. 数据一致性。 Jake Arrieta Authentic Jersey 适合一次写入多次读取的模型,客户端在文件没有被成功创建之前无法看到文件存在。
3. 文件会被分割成多个文件块,每个文件块被分配存储到数据节点上,而且根据配置会由复制文件块来保证数据的安全性。 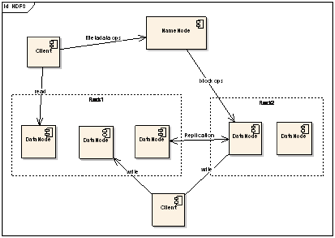 上图中展现了整个HDFS三个重要角色:NameNode、DataNode和Client。NameNode可以看作是分布式文件系统中的管理者,主要负责管理文件系统的命名空间、集群配置信息和存储块的复制等。 New Balance buty męskie NameNode会将文件系统的Meta-data存储在内存中,这些信息主要包括了文件信息、每一个文件对应的文件块的信息和每一个文件块在DataNode的信息等。DataNode是文件存储的基本单元,它将Block存储在本地文件系统中,保存了Block的Meta-data,同时周期性地将所有存在的Block信息发送给NameNode。Client就是需要获取分布式文件系统文件的应用程序。这里通过三个操作来说明他们之间的交互关系。 文件写入: 1. Client向NameNode发起文件写入的请求。 2. Fjallraven Kanken España NameNode根据文件大小和文件块配置情况,返回给Client它所管理部分DataNode的信息。 3. Client将文件划分为多个Block,根据DataNode的地址信息,按顺序写入到每一个DataNode块中。 Adidas Zx 850 Homme 文件读取: 1. Client向NameNode发起文件读取的请求。 Chaussures Femme Air Jordan
上图中展现了整个HDFS三个重要角色:NameNode、DataNode和Client。NameNode可以看作是分布式文件系统中的管理者,主要负责管理文件系统的命名空间、集群配置信息和存储块的复制等。 New Balance buty męskie NameNode会将文件系统的Meta-data存储在内存中,这些信息主要包括了文件信息、每一个文件对应的文件块的信息和每一个文件块在DataNode的信息等。DataNode是文件存储的基本单元,它将Block存储在本地文件系统中,保存了Block的Meta-data,同时周期性地将所有存在的Block信息发送给NameNode。Client就是需要获取分布式文件系统文件的应用程序。这里通过三个操作来说明他们之间的交互关系。 文件写入: 1. Client向NameNode发起文件写入的请求。 2. Fjallraven Kanken España NameNode根据文件大小和文件块配置情况,返回给Client它所管理部分DataNode的信息。 3. Client将文件划分为多个Block,根据DataNode的地址信息,按顺序写入到每一个DataNode块中。 Adidas Zx 850 Homme 文件读取: 1. Client向NameNode发起文件读取的请求。 Chaussures Femme Air Jordan
fjallraven kanken classic 16 L 2. NameNode返回文件存储的DataNode的信息。 3. Client读取文件信息。 Adidas ZX Flux Heren 文件Block复制: 1. NameNode发现部分文件的Block不符合最小复制数或者部分DataNode失效。 2. 通知DataNode相互复制Block。 3. DataNode开始直接相互复制。 HDFS的几个设计特点(对于框架设计值得借鉴): 1. Block的放置:默认不配置。一个Block会有三份备份,一份放在NameNode指定的DataNode,另一份放在与指定 DataNode非同一Rack上的DataNode,最后一份放在与指定DataNode同一Rack上的DataNode上。备份无非就是为了数据安全,考虑同一Rack的失败情况以及不同Rack之间数据拷贝性能问题就采用这种配置方式。 adidas messi astro 2. 心跳检测DataNode的健康状况,如果发现问题就采取数据备份的方式来保证数据的安全性。 3. 数据复制(场景为DataNode失败、需要平衡DataNode的存储利用率和需要平衡DataNode数据交互压力等情况):这里先说一下,使用HDFS的balancer命令,可以配置一个Threshold来平衡每一个DataNode磁盘利用率。例如设置了Threshold为 10%,那么执行balancer命令的时候,首先统计所有DataNode的磁盘利用率的均值,然后判断如果某一个DataNode的磁盘利用率超过这个均值Threshold以上,那么将会把这个DataNode的block转移到磁盘利用率低的DataNode,这对于新节点的加入来说十分有用。 4. 数据交验:采用CRC32作数据交验。在文件Block写入的时候除了写入数据还会写入交验信息,在读取的时候需要交验后再读入。 5. NameNode是单点:如果失败的话,任务处理信息将会纪录在本地文件系统和远端的文件系统中。 6. 数据管道性的写入:当客户端要写入文件到DataNode上,首先客户端读取一个Block然后写到第一个DataNode上,然后由第一个DataNode传递到备份的DataNode上,一直到所有需要写入这个Block的NataNode都成功写入,客户端才会继续开始写下一个 Block。 7. 安全模式:在分布式文件系统启动的时候,开始的时候会有安全模式,当分布式文件系统处于安全模式的情况下,文件系统中的内容不允许修改也不允许删除,直到安全模式结束。 Nike Air Max Très pas cher 安全模式主要是为了系统启动的时候检查各个DataNode上数据块的有效性,同时根据策略必要的复制或者删除部分数据块。运行期通过命令也可以进入安全模式。在实践过程中,系统启动的时候去修改和删除文件也会有安全模式不允许修改的出错提示,只需要等待一会儿即可。 在Hadoop的系统中,会有一台Master,主要负责NameNode的工作以及JobTracker的工作。 Cheap Fjallraven Kanken Bags JobTracker的主要职责就是启动、跟踪和调度各个Slave的任务执行。还会有多台Slave,每一台Slave通常具有DataNode的功能并负责TaskTracker的工作。TaskTracker根据应用要求来结合本地数据执行Map任务以及Reduce任务。 说到这里,就要提到分布式计算最重要的一个设计点:Moving Computation is Cheaper than Moving Data。就是在分布式处理中,移动数据的代价总是高于转移计算的代价。 Nike Air Max TN Homme asics gel noosa donna 简单来说就是分而治之的工作,需要将数据也分而存储,本地任务处理本地数据然后归总,这样才会保证分布式计算的高效性。 大致优点及使用的场景(没有不好的工具,只用不适用的工具,因此选择好场景才能够真正发挥分布式计算的作用): 1. 可扩展:不论是存储的可扩展还是计算的可扩展都是Hadoop的设计根本。 2. 经济:框架可以运行在任何普通的PC上。 3. 可靠:分布式文件系统的备份恢复机制以及MapReduce的任务监控保证了分布式处理的可靠性。 4. 高效:分布式文件系统的高效数据交互实现以及MapReduce结合Local Data处理的模式,为高效处理海量的信息作了基础准备。 Indiana Pacers 使用场景:个人觉得最适合的就是海量数据的分析,其实Google最早提出MapReduce也就是为了海量数据分析。同时HDFS最早是为了搜索引擎实现而开发的,后来才被用于分布式计算框架中。海量数据被分割于多个节点,然后由每一个节点并行计算,将得出的结果归并到输出。同时第一阶段的输出又可以作为下一阶段计算的输入,因此可以想象到一个树状结构的分布式计算图,在不同阶段都有不同产出,同时并行和串行结合的计算也可以很好地在分布式集群的资源下得以高效的处理。 二、首先介绍安装环境: OS:centos5.5最小化安装,选择了组件 base,devlopment libraries development tools editors text-base internet 这几个组件,其他的一概不选。安装系统完毕,直接进行yum update -y &升级。 在终端输入setup命令 选择firewall configuration 将security level 与SELinux 改为disabled,目的是为了避免在安装调试时产生不必要的麻烦,在系统安装完成后,可以自己去调试安全部分,在这里将不作详细介绍。 A:改变系统语言 # vi /etc/sysconfig/i18n 输入以下信息 LANG=”en_US” #LANG=”zh_CN.UTF-8″ SUPPORTED=”zh_CN.UTF-8:zh_CN:zh:zh_TW.UTF-8:zh_TW:zh:en_US.UTF-8:en_US:en” SYSFONT=”latarcyrheb-sun16″ B:关闭selinux # vi /etc/selinux/config 更改一下项目 SELINUX=disable C:去除IPV6 # vi /etc/modprobe.conf 添加以下项目 alias net-pf-10 off alias ipv6 off 三、组件安装 JavaSDK下载:到http://java.sun.com/javase/downloads/widget/jdk6.jsp下载jdk-6u20-linux-i586.bin文件 Hadoop安装文档可以到以下查看http://hadoop.apache.org/common/docs/ 下载可以到以下网址:http://www.apache.org/dyn/closer.cgi/hadoop/core/ 本次实验使用版本为: hadoop-0.21.0.tar.gz jdk-6u21-linux-i586.bin 主机ip 地址分配如下:主控服务器Master server: 192.168.1.101 存储块服务器slave servers: 192.168.1.102和192.168.1.103 客户端主机 (clients): 192.168.1.x 1) 主控服务器安装(slave服务器也同样操作) 添加hadoop用户 # useradd mfs hadoop 安装java # cp jdk-6u21-linux-i586.bin /usr/local # chmod +x jdk-6u21-linux-i586.bin # ./jdk-6u21-linux-i586.bin 修改环境变量,在/etc/profile添加(其中hadoop的变量为待会hadoop的安装路径) export JAVA_HOME=/usr/local/jdk1.6.0_21 export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib export PATH=$JAVA_HOME/lib:$JAVA_HOME/jre/bin:$PATH export HADOOP_HOME=/hadoop/hadoop/ export PATH=$PATH:$HADOOP_HOME/bin export HBASE_HOME=/hadoop/hbase 生效环境变量 # source /etc/profile 安装hadoop # cp hadoop-0.21.0.tar.gz /home/hadoop # tar xzf hadoop-0.21.0.tar.gz 配置hadoop # cd /home/hadoop/hadoop-0.21.0/conf 修改core-site.xml文件, fs.default.name hdfs://192.168.1.101:54310/ hadoop.tmp.dir /home/hadoop/tmp 修改hdfs-site.xml文件, dfs.replication 2 修改mapred-site.xml文件 mapred.job.tracker hdfs://192.168.1.101:54311/ 添加java环境变量 # echo “export JAVA_HOME=/usr/local/jdk1.6.0_21″ >> hadoop-env.sh 修改masters和slaves文件 Masters文件添加192.168.1.101(master)的IP地址或计算机名 Slaves文件添加192.168.1.102/103(slaves) 的IP地址或计算机名如 # echo 192.168.1.101 >> masters # echo 192.168.1.102 >> slaves # echo 192.168.1.103 >> slaves 至此hadoop组件安装完毕 2) 创建ssh免密码认证建立Master到每一台Slave的SSH受信证书。由于Master将会通过SSH启动所有Slave的 Hadoop,所以需要建立单向或者双向证书保证命令执行时不需要再输入密码。 Nike Air Max 2017 Pas Cher 在Master和所有的Slave机器上执行: # ssh-keygen -t rsa 为生成的id_rsa.pub改名,并复制到各slave服务器 # cd /root/.ssh/ # cp id_rsa.pub authorized_keys # scp authorized_keys root@192.168.1.102:/root/.ssh/ # scp authorized_keys root@192.168.1.103:/root/.ssh/ 修改所有服务器的/etc/ssh/sshd_config,把GSSAPIAuthentication的值设置为no,起到加速作用重启ssh服务 3) 启动服务器首先格式化namenode(slaves)服务器 # hadoop namenode -format 如果报错,jdk等错误,请检查slave服务器的java环境配置是否正确启动服务 # ./bin/start-all.sh 启动后可以用url查看http://192.168.1.101:50070/dfshealth.jsp 相关命令 * start-all.sh 启动所有的Hadoop守护。包括namenode, datanode, jobtracker, tasktrack * stop-all.sh 停止所有的Hadoop * start-mapred.sh 启动Map/Reduce守护。